Reading Note of CppPrimer-Chapter4
Expressions
Precedence & Associative & Evaluation Order
优先级 (Precedence)
优先级决定了在表达式里面不同的运算符的运算顺序;高优先级运算符的运算对象比起低优先级运算符的运算对象会更紧密结合在一起;
拿不准的时候用括号强制规定运算顺序,括号无视优先级和结合律
结合律 (Associative)
运算符的结合性是指相同优先级的运算符在同一个表达式中,且没有括号的时候,运算符 (operator) 和操作数 (operand) 的结合方式,通常有从左到右结合和从右到左结合两种方式:
- 左结合律:Left-to-right
- 右结合律:Right-to-left
常见 C++ 运算符的优先级和结合律
![ch4-precedence-associative]()
求值顺序:
运算对象的求值顺序和优先级及结合律无关
1
int a = f() + g() * h() + j();
- 优先级决定 g 的返回值应该和 h 的返回值相乘
- 结合律决定 f 的返回值要加上 g*h 的乘积再加上 j 的返回值
- 对于这些函数的调用顺序却没有规定
优先级虽然规定了对象的组合方式,但是没有说明对象按照什么顺序求值
有四种二元运算符规定了运算顺序,包含
&&、||、?:、,1
2
3
4
5
6
7
8
9
10
11
12
13if (a && b){
// if a is false, b will not be evaluated
}
if (a || b){
// if a is true, b will not be evaluated
}
// if a > b, c = a else c = b
int c = a > b ? a : b;
for (int i=0; i<10; i++,c++){ // i++, then discard i, then c++ and return c
}如果一个表达式里面改变了某个对象的值,该表达式的其他地方尽量不要再使用这个对象,
*iter++是例外;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// warning: unsequenced modification and access to 'i' [-Wunsequenced]
// possible output:
// 0 1
// 1 1
int i=0;
std::cout << i << i++; // undefined behavior until C++17
a[i] = i++; // undefined behavior until C++17
n = ++i + i; // undefined behavior
// 只是规定了*运算前f1()和f2()都是执行过的,没有规定是先算f1还是f2;如果f1和f2相关的话,会产生未定义的结果;
int x = f1() * f2();
// warning: unsequenced modification and access to 'a' [-Wunsequenced]
int i = 100;
i = ++i + 2; // undefined behavior until C++11
i = i++ + 2; // undefined behavior until C++17
f(i = -2, i = -2); // undefined behavior until C++17
f(++i, ++i); // undefined behavior until C++17, unspecified after C++17
i = ++i + i++; // undefined behavior
C++11 “按顺序早于” 规则 (Sequenced-before rules )
表达式的求值主要包含两个部分:
- 值计算 (value computations):主要涉及到决定对象的身份 (glvaue evaluation,比如表达式返回了某个对象的引用) 或者读取对象先前被赋的值 (prvalue evaluation,比如某个表达式返回了数字或者其他右值)
- 副作用 (side effects):副作用主要涉及到对 volatile 变量的读写操作、对一般对象的写操作、调用 I/O 库函数、或者是调用了任何执行以上任一操作的函数
顺序的定义:
“按顺序早于 (sequenced-before)” 是同一线程中的求值之间的非对称的、传递的对偶关系;C++ 定义了几种顺序:
- 若 A 按顺序早于 (sequenced before) B,则 A 的求值将在 B 的求值开始前完成
- 若 A 不按顺序早于 (not sequenced before) B 而 B 按顺序早于 (sequenced before) A,则 B 的求值将在 A 的求值开始前完成。
- 若 A 不按顺序早于 (not sequenced before) B 而 B 不按顺序早于 (not sequenced before) A,则存在两种可能:
- A 与 B 的求值是无顺序的 (unsequenced) :它们能以任何顺序进行,并可能重叠(在同一执行线程内,编译器可以将组成 A 与 B 的 CPU 指令交错)
- A 与 B 的求值是顺序不确定的 (indeterminately sequenced) :它们可以任意顺序进行但不可重叠,A 在 B 前完成,或 B 在 A 前完成。下次求值相同表达式时顺序可以相反。
具体规则:
每个全表达式 (full-expression) 的值的计算 (value computation) 和副作用 (side effect) 都是按顺序早于另一个后续的全表达式的,全表达式包含:
任何运算符
e.g. +,-,*,/,%的各操作数的值计算 (value computation)(但非副作用 (but not side effect)) 均按顺序早于 (sequenced before) 该运算符结果的值计算 (但非副作用)函数调用 (无论函数是否内联,是否使用显式函数调用语法) 时,函数的实参以及函数后缀表达式相关的值计算以及副作用均顺序早于 (sequenced before) 函数体里面的表达式
后自增与后自减 (
i++, i--) 运算符的值计算按顺序早于 (sequenced before) 其副作用前自增与前自减 (
++i, --i) 运算符的副作用按顺序早于 (sequenced before) 其值计算逻辑与 (
and) 运算符&&和内建逻辑或 (or) 运算符||的左操作数的值计算和副作用,按顺序早于 (sequenced before) 右操作数的值计算和副作用条件运算符
?:中的第一个表达式关联的值计算和副作用,都按顺序早于 (sequenced before) 与第二或第三表达式关联的值计算和副作用逗号运算符
,的左参数的值计算和副作用均按顺序早于 (sequenced before) 右参数的值计算和副作用赋值运算符
=和复合赋值运算符e.g. +=, *=的 ** 副作用 (即修改左参数)**,均按顺序晚于 (sequenced after) 左右参数的值计算 (但非副作用),且按顺序早于 (sequenced before) 赋值表达式的值计算 (即早于返回指代被修改对象的引用之时)列表初始化中,在大括号中用逗号分隔的初始化器子句的值计算和副作用都按顺序早于 (sequenced before) 逗号后的初始化器子句的值计算和副作用,比如
int i=0; std::vector<int> vec = {i++, i++, i++, i++};是确定的分配函数
operator new的调用相对于new表达式中构造函数参数的求值来说,C++17 前是顺序不确定的 (indeterminately sequenced),C++17 起是按顺序早于 (sequenced before) 它;比如int i=0; int* ptr = new int(i++);C++14 起,函数返回时,返回结果的临时量的复制初始化 (copy initialization) 按顺序早于 (sequenced before) 在
return语句的操作数末尾处对所有临时量的销毁,而这些临时量的销毁进一步按顺序早于 (sequenced before) 对return语句所在的块 (block scope) 的所有局部变量的销毁C++17 起,指明函数的表达式按顺序早于 (sequenced before) 参数表达式和默认实参。比如
int i=0; cout << i << ++i;在 C++17 之前是不确定的,但是是 C++17 后是肯定先输出0再输出1C++17 起,函数调用表达式中,形参的初始化的值计算和副作用相对于任何其他形参的初始化的值计算和副作用是顺序不确定的 (indeterminately sequenced),比如
void print(int a, int b){std::cout << a << b;}; int i=0; print(++i, ++i);的输出是不确定的,可能输出12也可能输出21C++17 起,用运算符写法进行调用时,重载的运算符均遵循其所重载的内建运算符的定序规则
C++17 起,下标表达式
E1[E2]中,E1 的值计算和副作用均按顺序早于 (sequenced before) E2 的值计算和副作用,如a[i++][i++] = 1;在 C++17 之前可能是a[0][1] = 1也可能是a[1][0];但是从 C++17 起是确定的C++17 起,成员指针表达式
E1.*E2或E1->*E2中,E1 的值计算和副作用都按顺序早于 (sequenced before) E2 的值计算和副作用C++17 起,移位运算符表达式
E1<<E2和E1>>E2中,E1 的值计算和副作用都按顺序早于 (sequenced before) E2 的值计算和副作用,比如i++ << i;C++17 起,赋值运算符
E1=E2和复合赋值运算符E1@=E2中,E2 的值计算和副作用均按顺序早于 (sequenced before) E1 的值计算和副作用,比如i = i++ + 2;C++17 起,带括号的初始化器中的逗号分隔的每个表达式,如同函数调用一般求值,是顺序不确定的 (indeterminately sequenced),比如
(i++, i++, i++, i++)是不确定的
未定义行为
若标量对象上的一项副作用相对于同一标量对象上的另一副作用为无顺序,则其行为未定义
1
2
3
4
5i = ++i + 2; // C++11 前为未定义行为(rule5, 自增先于值计算,rule9,左右参数值计算先于左值副作用)
i = i++ + 2; // C++17 前为未定义行为(rule19, 右值副作用早于左值)
f(i = -2, i = -2); // C++17 前为未定义行为(rule14)
f(++i, ++i); // C++17 前为未定义行为,C++17 起为未指明,可以是f(0,1)也可以是f(1,0)(rule14)
i = ++i + i++; // 未定义行为(rule2, 仅仅规定了操作数和运算结果的关系,没有规定运算数之间的关系)若标量对象上的副作用相对于使用同一标量对象的值的值计算为无顺序,则其行为未定义
1
2
3cout << i << i++; // C++17 前为未定义行为(rule13)
a[i] = i++; // C++17 前为未定义行为(rule19)
n = ++i + i; // 未定义行为(rule2, 仅仅规定了操作数和运算结果的关系,没有规定运算数之间的关系)

Common Operators
算术运算符
算术运算符的结果是右值,包含一元
+(pos)-(neg),二元+-*/%;C++11 规定商一律向 0 取整,即丢弃小数;
1
2
3
4std::cout << "2/2: " << 2/2 << std::endl; // 1
std::cout << "1/2: " << 1/2 << std::endl; // 0
std::cout << "-1/2: " << -1/2 << std::endl; // 0
std::cout << "-2/2: " << -2/2 << std::endl; // -1C++11 规定
取余或者取模运算:m%n,如果 m n 均为整数且 n 不为 0,则它的符号与 m 相同1
2
3
421 % 6; // 21-3*6=3
21 % 7; // 21-3*7=0
-21 % 8; // -21-(-2*8)=-5
21 % -5; // 21-(-5*-4)=1
逻辑关系运算符
结合律
除了
逻辑非满足右结合律,其他都满足左结合律;优先级
逻辑非(!)>大于/小于(>/<)>等于/不等(==/!=)>逻辑与(&)>逻辑或|;
赋值运算符
赋值运算符返回的是左侧对象,所以可以有多重赋值语句,例如:
1
2int ival, jval;
ival = jval = 1; //jval=1将返回jval,于是ival == jval == 1赋值运算满足右结合律
赋值运算符优先级较低,所以通常需要给赋值部分加上括号使其符合我们的本意
1
2
3
4
5int i = get_value();
while (i != 42){
i = get_value();
// ...
}可以简写为:
1
2
3
4int i = 0;
while ((i=get_value()) != 42){
// ...
}如果不加括号,就不是我们期望的结果:
1
2
3
4
5
6int i = 0;
// first calc get_value() != 42, then assign the value to i then return i
// now, i != get_value() but i == true or i == false
while (i=get_value() != 42){
// ...
}cpp11 允许使用花括号括起来的初始值列表 (initializer-list) 作为赋值语句的右侧运算对象;
初始值列表
{}都可以为空,此时执行值初始化;如果左侧运算对象是内置类型,则初始值列表最多包含一个值,且该值即使转换的话其所占空间也不应大于目标类型的空间,即 narrowing-checking,这样的赋值更安全;
如果左侧运算对象是类类型,则赋值的细节由类本身的拷贝赋值函数决定;
1
2int k = 0;
k = {3.14}; // type 'double' cannot be narrowed to 'int' in initializer list [-Wc++11-narrowing]
递增运算符
前置(++i)首先将运算对象 + 1,然后返回这个更新后的运算对象的值;
后置(i++)将运算对象的值 + 1,但是求值结果返回的是对象 b 改变前的副本;
前置运算作用于左值对象返回左值,但是后置运算作用于左值对象返回右值;建议养成使用前值运算的习惯;
1
2
3int i = 1;
int &&ipp = i++;
int& ip = ++i;如果需要使用递增或者递减之前的值,则使用后置递增递减,如 iter++;
箭头 / 点运算符
箭头运算符作用于一个指针的类型,结果是左值;点运算符可能返回左值也可能返回右值;
箭头运算符 (
->),相当于先解引用,然后调用点运算符 (.),即:1
2
3ptr->a;
// similar to
(*ptr).a;条件运算符
条件运算符的优先级很低,在很长的表达式中嵌套条件运算子表达式的时候一般要加上括号
1
2
3
4
5
6std::cout << ((grade < 60) ? : "fail" : "pass"); // pass or fail
// warning: operator '?:' has lower precedence than '<<'; '<<' will be evaluated first [-Wparentheses]
std::cout << (grade < 60) ? : "fail" : "pass"; // 1 or 0
std::cout << grade < 60 ? : "fail" : "pass"; // error, compare std::cout with 60位运算符
位运算符作用于整数将整数看作二进制位的集合,所以位运算符同样可以应用于
std::bitset符号位怎么处理没有明确的定义,所以建议只在无符号整数上使用位运算;
包含二元:
>><<&|^, 一元:~,他们也属于算数运算符注意区分位运算符和逻辑运算符,比如
&vs&&;判断一个数是奇数还是偶数,可以通过两种方法来判断;
1
2
3if (s % 2 == 1){};
// equal to
if (s & 0x01) {};数的分类
1
2
3
4
5数:实数、虚数;
实数分类:有理数、无理数;
有理数分类:整数、小数;
整数分类:正整数、负整数;
正整数分类:奇数、偶数。
sizeof 运算符
运算对象有两种形式:
1
2sizeof (type); // return byte
sizeof (expr); // 返回表达式结果类型的大小,并不实际计算表达式的值,即使是空指针sizeof 运算符的结果:
- 对 char 或者类型为 char 的表达式返回 1;
- sizeof 对引用返回的是引用的对象的大小;
- 对指针返回的是指针的大小;
- 对解引用返回的是指针指向的对象的大小,无需指针有效;
- 对数组的返回相当于把数组里面的每个元素都执行了 sizeof,不会把数组当作指针看待;
sizeof 的返回值是 constexpr, 所以可以用 sizeof 的结果声明数组的维度;sizeof 返回的单位是 byte;
1
2
3sizeof(ia); // 数组所占byte数
sizeof(*ia); // 数组第一个成员所占byte数
constexpr int sz = sizeof(ia) / sizeof(*ia); // return array size
逗号运算符
运算顺序理解:首先将左侧的表达式求值,然后将左侧的值舍弃;逗号运算符的返回结果是逗号右侧的值
1
int a = someVale ? —x, —y : ++x, ++y;
Implicit Conversion
算术隐形转换
整数提升
负责将小类型数据转换为大类型数据
1
2
3
4
5
6int a = 1;
char b = 2;
short c = 3;
auto d = a + b; // integral promotion, char is promoted to int
auto e = a + c; // integral promotion, short is promoted to int无符号类型的隐形转换
如果两个运算符的运算对象类型不一致,首先进行的就是整数提升;
如果运算符的两个运算对象符号不同,无符号类型不小于有符号的,则有符号的转换为无符号的类型
1
2
3int a = 1;
unsigned b = 2;
auto c = a + b; // c is unsigned, b is implicitly converted to unsigned如果有符号的运算符类型更大,此时如果有符号类型可以存的下无符号类型,则无符号转成有符号,反之亦反;
1
2
3
4
5
6
7int a = 1;
unsigned char b = 1;
auto c = a + b; // c is int, range of unsigned char is larger than range of int
long d = 1;
unsigned int e = 2;
auto f = d + e; // f is long, range of unsigned int is larger than range of long
其他隐形转换
- 数组转换为指针,但是除了 decltype、sizeof、typeid、& 等运算符
- 指针转换:
- 0 和 nullptr 转换成任意指针类型
- 任意非常量指针可以转换为 void*
- 任意非常量指针转换为 const void*
- 布尔类型:算术类型或指针类型自动向布尔类型转换
- 常量:任意底层非常量类型可以转换为常量类型 (non-const to low level const)
- 类类型的转换
- 字符串常量到字符串的转换
Explicit Conversion
显式类型转换
主要包括
static_cast,dynamic_cast,const_cast,reinterpret_cast几种类型;static_cast
任何具有明确定义的类型转化,只要不包含底层 const (去掉底层 const),都可以使用 static_cast,特别是把一个大的类型转换为小的类型,比如将派生类转换为基类;
也可以转化编译器无法自动执行的类型转化,比如找回 void * 地址的值
1
2void *p = &d;
double *dp = static_cast<double*>(p);dynamic_cast
用于将基类的指针或者引用安全地转换为派生类的指针或引用或者将派生类的指针或者引用安全地转换为基类的指针和引用,后者的功能和 static_cast 相同;一般要求基类需要有虚函数;有以下形式;
因为对于派生类的引用或者指针可以隐式转换为基类的引用和指针,所以在不能使用虚函数的时候(因为虚函数会动态绑定),是存在需求将基类的引用或指针转化为派生类的引用或指针然后调用派生类的方法的;
1
2
3dynamic_cast<Type *>(e);
dynamic_cast<Type &>(e);
dynamic_cast<Type &&>(e);e 的形式是以下三种情况之一,才会转换成功,否则会转换失败:
e 是 Type 的公有派生类
e 是 Type 的公有基类
e 和 Type 类型一致
如果转换指针类型失败,会返回
01
2
3
4
5
6if(Derived* dp = dynamic_cast<Derived>(base_pt)){ // 可以确保类型转换和结果检查在一条语句完成
// use dp as Derived*
}
else{
// use dp as base_pt
}如果转换引用类型失败,会返回 bad_cast 异常
1
2
3
4
5
6
7
8void f(const Base& b){
try{
// use d as Derived&
const Derived& d = dynamic_cast<const Derived &>(b);
}catch(std::bad_cast){
// use b as Base
}
}dynamic_cast 主要用于类层次间的上行转换和下行转换
在类层次间进行上行转换时,dynamic_cast 和 static_cast 的效果是一样的;在进行下行转换时,dynamic_cast 具有类型检查的功能,比 static_cast 更安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Base {
public:
int m_iNum;
virtual void foo();
};
class Derived:public Base {
public:
char *m_szName[100];
};
void func(Base *pb){
Derived *pd1 = static_cast<Derived *>(pb);
Derived *pd2 = dynamic_cast<Derived *>(pb);
}在上面的代码段中,
如果 pb 实际指向一个 Derived 类型的对象,pd1 和 pd2 是一样的,并且对这两个指针执行 Derived 类型的任何操作都是安全的;
如果 pb 实际指向的是一个 Base 类型的对象,那么 pd1 将是一个指向该对象的指针,对它进行 Derived 类型的操作将是不安全的(如访问 m_szName),而 pd2 将是一个空指针 (即 0,因为 dynamic_cast 失败)。dynamic_cast 还可以用于类之间的交叉转换,即可以在继承于同一基类的兄弟派生类间转换(虽然会失败)但是 static_cast 不可以
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Base {
public:
int m_iNum;
virtual void f(){}
};
class Derived1 : public Base{
};
class Derived2 : public Base{
};
Derived1 *pd1 = new Drived1;
pd1->m_iNum = 100;
Derived2 *pd2s = static_cast<Derived2 *>(pd1); //compile error
Derived2 *pd2d = dynamic_cast<Derived2 *>(pd1); //pd2d is NULL 0x01
2static_cast from 'Derived1 *' to 'Derived2 *', which are not related by inheritance, is not allowed
Derived2 *pd2s = static_cast<Derived2 *>(pd1); //compile errordynamic_cast 在派生类和基类之间转化,需要基类有虚函数
1
2
3
4
5
6
7class Base {
public:
int m_iNum;
//virtual void foo(); // no virtual func
};
Derived *pd2 = dynamic_cast<Derived *>(pb);1
2error: 'Base' is not polymorphic
Derived *pd2 = dynamic_cast<Derived *>(pb);Base 要有虚函数,否则会编译出错;static_cast 则没有这个限制。
这是由于运行时类型检查需要运行时类型信息,而这个信息存储在类的虚函数表(关于虚函数表的概念,详细可见 <Inside c++ object model>)中,只有定义了虚函数的类才有虚函数表,没有定义虚函数的类是没有虚函数表的。
const_cast
const_cast 只能改变运算对象的
底层const,即改变指向的对象是不是可以修改这个属性如果指针或者引用指向的对象本身不是常量,const_cast 才是合法的;
或者他们本身是常量,但转换后不对这个变量作写操作,那么这也是合法的,比如下面第二条,则是未定义的行为;
比如一个变量本身是 non-const,通过中间加上 const 关键字,此时再从 const 转为 non-const 就可以使用 const_cast;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int value = 1024;
const int &value_ref = value; // 引用, 不可改变value的值
const int *value_pointer = &value; // 指针, 不可改变value的值
int * const value_pointer1 = &value;
auto r = const_cast<int &>(value_ref); // 将value_ref从const int &转换成int &
auto p = const_cast<int *>(value_pointer); // 将value_ref从const int *转换成int *
auto p1 = const_cast<int *>(value_pointer1);
r = 666; // valid
std::cout << value << std::endl;
*p = 233; // valid
std::cout << value << std::endl;
*p1 = 111; // valid
std::cout << value << std::endl;比如调用了一个参数不是 const 的函数,而我们要传进去的实际参数确实 const 的,但是我们知道这个函数是不会对参数做修改的,比如调用了别人的库
1
2
3
4
5
6
7
8
9
10
11// third party library
void Printer (int* val, std::string seperator = "\n") {
std::cout << val<< seperator << std::endl;
}
int main(void) {
const int consatant = 20;
//Printer(consatant); //Error: invalid conversion from 'int' to 'int*'
Printer(const_cast<int *>(&consatant));
return 0;
}再比如类的 const member function,对外是 const 的,但是保不齐内部需要修改自己的啥值,这时候可以把 this 指针转换为 non-const 的
1
2
3
4
5
6
7
8
9
10
11struct type {
int i;
type(): i(3) {}
void f(int v) const
{
// this->i = v; // compile error: this is a pointer to const
const_cast<type*>(this)->i = v; // OK as long as the type object isn't const
}
};如果他们指向的对象本身就是常量,且需要对转换后的变量作写操作,虽然编译可能会通过,但是结果未定义;
1
2
3
4
5
6
7
8
9
10const int value = 1024;
const int &value_ref = value; // 引用, 不可改变value的值
const int *value_pointer = &value; // 指针, 不可改变value的值
auto r = const_cast<int &>(value_ref); // 将value_ref从const int &转换成int &
auto p = const_cast<int *>(value_pointer); // 将value_ref从const int *转换成int *
// r = 666; // 未定义行为
// *p = 233; // 未定义行为reinterpret_cast
首先从英文字面的意思理解,interpret 是 “解释,诠释” 的意思,加上前缀 “re”,就是 “重新诠释” 的意思;cast 在这里可以翻译成 “转型”(在侯捷大大翻译的《深度探索 C++ 对象模型》、《Effective C++(第三版)》中,cast 都被翻译成了转型),这样整个词顺下来就是 “重新诠释的转型”。我们知道变量在内存中是以 “…0101…” 二进制格式存储的,一个 int 型变量一般占用 32 个位(bit)
参考下面的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
using namespace std;
int main(int argc, char** argv){
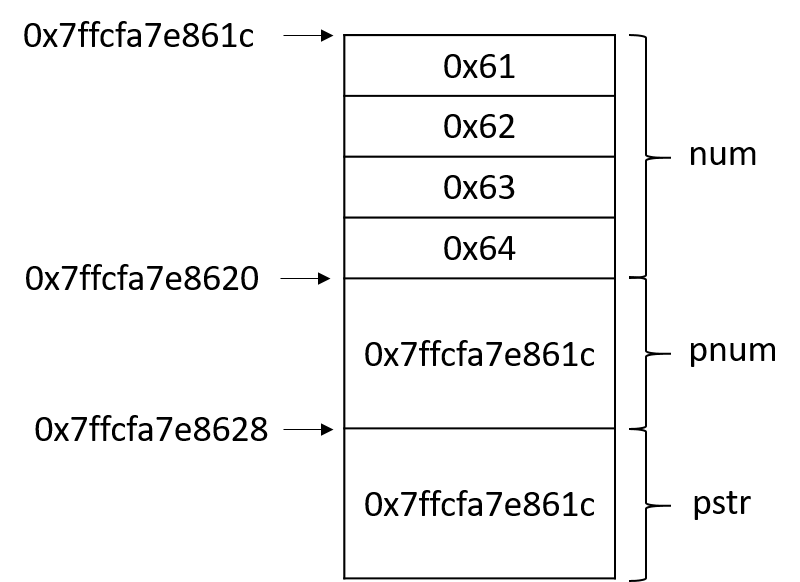
int num = 0x00636261; //用16进制表示32位int,0x61是字符'a'的ASCII码
int * pnum = #
char * pstr = reinterpret_cast<char *>(pnum);
cout<<"pnum指针的值: "<<pnum<<endl;
//直接输出pstr会输出其指向的字符串,这里的类型转换是为了保证输出pstr的值
cout<<"pstr指针的值: "<<static_cast<void *>(pstr)<<endl;
cout<<"pnum指向的内容: "<<hex<<*pnum<<endl;
cout<<"pstr指向的内容: "<<pstr<<endl;
return 0;
}
// output
pnum指针的值: 0x7ff7b790f6fc
pstr指针的值: 0x7ff7b790f6fc
pnum指向的内容: 636261
pstr指向的内容: abc将 pnum 和 pstr 两个指针的值输出,对比发现,两个指针的值是完全相同的,这是因为 “reinterpret_cast 运算符并不会改变括号中运算对象的值,而是对该对象从位模式上进行重新解释”。如何理解位模式上的重新解释呢?通过推敲代码 11 行和 12 行的输出内容,就可见一斑。
很显然,按照十六进制输出 pnum 指向的内容,得到 636261;但是输出 pstr 指向的内容,为什么会得到”abc” 呢?
在回答这个问题之前,先套用《深度探索 C++ 对象模型》中的一段话,“一个指向字符串的指针是如何地与一个指向整数的指针或一个指向其他自定义类型对象的指针有所不同呢?从内存需求的观点来说,没有什么不同!它们三个都需要足够的内存(并且是相同大小的内存)来放置一个机器地址。指向不同类型之各指针间的差异,既不在其指针表示法不同,也不在其内容(代表一个地址)不同,而是在其所寻址出来的对象类型不同。也就是说,指针类型会教导编译器如何解释某个特定地址中的内存内容及其大小。” 参考这段话和下面的内存示意图,答案已经呼之欲出了。
![ch4-reinterpret_cast]()
使用 reinterpret_cast 运算符把 pnum 从 int 转变成 char 类型并用于初始化 pstr 后,pstr 也指向 num 的内存区域,但是由于 pstr 是 char 类型的,通过 pstr 读写 num 内存区域将不再按照整型变量的规则,而是按照 char 型变量规则。一个 char 型变量占用一个 Byte,对 pstr 解引用得到的将是一个字符,也就是’a’。而在使用输出流输出 pstr 时,将输出 pstr 指向的内存区域的字符,那 pstr 指向的是一个的字符,那为什么输出三个字符呢?这是由于在输出 char 指针时,输出流会把它当做输出一个字符串来处理,直至遇到’\0’才表示字符串结束。对代码稍做改动,就会得到不一样的输出结果,例如将 num 的值改为 0x63006261, 输出的字符串就变为”ab”。
reference: https://zhuanlan.zhihu.com/p/33040213
强制类型转换干扰了正常的类型检查,因此不建议频繁使用,除非你真的知道你在做什么,尤其是 reinterpret_cast,改变了底层表示的类型;
decltype 作用于表达式的时候,对于左值右值有区别:
- 如果表达式的结果是左值,decltype作用于该表达式,得到的是引用类型,如假定int* p; 则decltype(*p)的类型为int&; - 当表达式结果是右值的时候,得到的是指针,如假定int* p,则decltype(&p)的类型为int **;