Reading Note of CppPrimer-Chapter11
Associative Containers
Overview
标准库提供了 8 个关联容器 (associative container),每个容器:
- 要么是一个 map,要么是一个 set;
- 要么允许相同的关键字,要么允许不同的关键字;区分看名字中是否有 multi
- 要么按顺序存储,要么按无序存储,无序使用哈希函数来组织元素;区分看名字中是否有 unordered
1
2
3
4
5
6
7
8std::map; // 有序,不允许相同关键字的map
std::set; // 有序,不允许相同关键字的set
std::multimap; // 有序,允许相同关键字的map
std::multiset; // 有序,允许相同关键字的set
std::unordered_map; // 无序、不允许相同关键字的map
std::unordered_set; // 无序、不允许相同关键字的set
std::unordered_multimap; // 无序、允许相同关键字的map
std::unordered_multiset; // 无序、允许相同关键字的set关联容器的初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20std::map<std::string, int> si_map; //默认初始化
std::set<std::string> s;
// initial list
std::set<int> s1 = {"A", "B", "A", "C"}; // 列表初始化
std::map<std::string, size_t> m = {{"Key1", "Value1"},
{"Key2", "Value2"}}; // 双层花括号列表初始化
// custom compare func
using value_type = int;
auto compare_func = [](value_type a, value_type b){return a>b;};
std::map<int, value_type, decltype(compare_func)> m(compare_func);
// copy from vector
std::vector<std::pair<std::string, int>> vec = {{"1",2}, {"2",3}};
std::vector<std::pair<std::string, int>> vec2 = {std::make_pair("1",2), std::make_pair("2",3)};
std::vector<std::pair<std::string, int>> vec3(1, std::make_pair("1",2));
std::map<std::string, int> m1(vec.begin(), vec.end());
// copy to vector
std::vector<std::pair<std::string, int>> vec1(m1.begin(),m1.end());关联容器对于关键字有限制:
- 对于 set,关键字就是容器类型;对于 map,关键字是 key;
- 对于有序关联容器,关键字必须定义元素的满足严格弱序 (
strict weak ordering,见 chapter10) 的比较方法; - 对于无序关联容器,他们是用
==来比较元素,同时他们还使用一个hash<key_type>类型的对象去生成每个元素的 hash 值;我们可以定义内置类型 (包含指针)、string、智能指针的无序容器;
关键字的比较函数 (comparer) 也是关联容器的一部分,可以在声明的时候指定,当我们创建一个对象的时候,以构造函数参数的形式传入容器作为关键字比较的函数;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// init compare function from struct with overload operator()
struct Point { double x, y; };
struct PointCmp {
bool operator()(const Point& lhs, const Point& rhs) const {
return lhs.x < rhs.x; // NB. intentionally ignores y
}
};
std::map<Point, double, PointCmp> mag = {
{ {5, -12}, 13 },
{ {3, 4}, 5 },
{ {-8, -15}, 17 }
};
// init compare function from function
bool comparation(const std::string& lhs, const std::string& rhs){
return lhs.size() > rhs.size()
}
std::map<std::string, int, decltype(comparation)*> str_order_by_size(comparation);
// init from lambda
auto cmpLambda = [&mag](const Point &lhs, const Point &rhs) { return mag[lhs] < mag[rhs]; };
//You could also use a lambda that is not dependent on local variables, like this:
//auto cmpLambda = [](const Point &lhs, const Point &rhs) { return lhs.y < rhs.y; };
std::map<Point, double, decltype(cmpLambda)> magy(cmpLambda);std::pair
类似于 vector,pair 的默认构造函数对数据成员进行值初始化;map 的
value_type是一个 pair1
2
3
4
5
6
7
8
9
10
11
12
13
14// pair constructor
std::pair<std::string, std::string> anon; //默认初始化
std::pair<std::string, std::string> author{"Pang", "Wong"}; //列表初始化, 亦可作为返回值
std::pair<std::string, std::string> func{
// do something
return {"Pang", "Wong"}
}
// make_pair
auto p = std::make_pair("Pang", "Wong");
// for range loop
std::map<std::string, size_t> m = {{"Key1", "Value1"}, {"Key2", "Value2"}}; // 双层花括号
for (const auto &pair : m){
std::cout << m.first << ", " << m.second << std::endl;
}value_type and key_type and mapped_type.
set 的
key_type和value_type都是关键字 Key 本身的类型;map 的
key_type是 key 的类型,mapped_type是 map 模版的第二个参数,value_type是一个 first 元素为 const Key 的 pair:std::pair<const Key, T>;其他的关联容器的
type alias和对应的map、set一致解引用一个关联容器的迭代器的时候,会得到一个类型为
value_type的引用;set 的迭代器都是 const 的;
1
2
3
4
5
6
7
8
9
10auto map_it = word_count,begin();
std::cout << map_it->first; // valid
map_it->first = "123"; // invalid, const
map_it->second = 12; // valid
std::set<std::string> sset = {"1", "2", "3"};
auto set_it = sset.begin();
if (set_it != sset.end()){
*set_it = "abc"; // invalid, const
}当遍历一个有序容器的时候,迭代器是按照关键字
Comparer定义的顺序来遍历的,而不是插入容器的顺序;默认就是从小到大;这就是为什么称为有序容器
Associative Container Operation
find and count
对于不允许关键字重复的关联容器,搜索某个关键字用
find()就可以;但是对于允许重复的关键字,count()能找出重复的次数;1
2
3
4
5
6
7
8
9std::multimap<std::string, std::string> authors;
auto entries = authors.count("PangWong");
auto iter = authers.find("PangWong");
while (entries){
std::cout << iter->second << std::endl;
iter++;
entries--;
}container access
std::map 可以用
operator []和at来获取以一个关键字相关联的值;复杂度为o(logn)与其他下标运算不同的是,如果关键字不在 map 里面,会为他创建一个这个关键字的元素并插入 map,关键值进行值初始化;由于
operator[]可能插入下一个元素,所以只可以对non-const map使用下标操作;at操作会检查 key 是不是存在,如果访问一个不存在 map 的 key,会报错std::out_of_range如果只是想知道一个关键字是不是在 map 中,不存在也不想添加元素的时候,是不能用
operator []或者at来判断的,可以用find;1
2
3
4
5std::map<int, int> m;
if (m[1] == 1){ // will insert (1, 0) to m
std::cout << "key 1 is in map" << std::endl;
}
const std::maperase
关联容器的删除有几种不同的形式:
1
2
3c.erase(key); // 删除知道的key值,返回删除的个数,
c.erase(iterator); // 删除指定迭代器的元素,返回被删元素的下一个元素;
c.erase(iterator_begin, iterator_end); // 删除范围insert
1
2
3c.insert(v); // insert key v, different behavior for set/map or multiset/map
c.insert(p, v); // insert key v given a hint at iter p
c.insert(initializer-list);// for map/set, only insert item not in container; otherwise insert every item对于 set 和 map,只有当给定元素不在容器中时才进行插入;
insert的参数是一个value type的pair,返回值是一个pair,pair->first是一个iterator,pair->second是一个bool,bool代表是否插入成功:1
pair<iterator, bool> insert (const value_type& val);
1
2
3
4auto ret = m.insert(std::make_pair("1", 1));
if (ret.second){
// insert successfully
}insert和operator [] assignment有区别,insert如果 key 存在会失败,但是assignment每次都会覆盖掉之前的值;1
2
3std::map<int, float> m = {{1, 0.99}, {0, 0.03}};
m.insert({1, 0.88}); // not insert, fail
m[1] = 0.88; // ok, not m[1] changed from 0.99 to 0.88对于 multiset 和 multimap,总是会插入给定元素,并返回指向新元素的迭代器
1
iterator insert (const value_type& val);
lower_bound and upper_bound and equal_range
lower_bound:>=,returns an iterator to the first element not less than the given keyupper_bound:>, returns an iterator to the first element greater than the given keyequal_range: returns a range containing all elements equivalent tovaluein the range[first, last).
如果元素不在容器中,则
lower_bound和upper_bound的返回值相同,都指向一个不影响排序的关键字插入顺序因此,使用
lower_bound和upper_bound会组成一个迭代器范围,这个 range 等价于equal_range的返回值1
2
3
4
5
6
7
8// same function with count and find
for (auto beg=authors.lower_bound(search_item), end=authors.upper_bound(search_item); beg!=end; beg++){
std::cout << beg->second << std::endl;
}
// equal to
for (auto pos=authors.equal_range(search_item); pos.first != pos.second; pos.first++){
std::cout << pos.first.second << std::endl;
}best practice
std::map::insertsuggested by Item 24 of Effective STL by Scott Meyers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20typedef map<int, int> MapType; // Your map type may vary, just change the typedef
MapType mymap;
// Add elements to map here
int k = 4; // assume we're searching for keys equal to 4
int v = 0; // assume we want the value 0 associated with the key of 4
MapType::iterator lb = mymap.lower_bound(k); // >=
if(lb != mymap.end() && !(mymap.key_comp()(k, lb->first))) // ==
{
// key already exists
// update lb->second if you care to
}
else
{
// the key does not exist in the map
// add it to the map
mymap.insert(lb, MapType::value_type(k, v)); // Use lb as a hint to insert,
// so it can avoid another lookup
}顺序关联容器算法复杂度
std::setis an associative container that contains a sorted set of unique objects of typeKey. Sorting is done using the key comparison function Compare. Search, removal, and insertion operations have logarithmic complexity. Sets are usually implemented as red-black trees.std::mapis a sorted associative container that contains key-value pairs with unique keys. Keys are sorted by using the comparison functionCompare. Search, removal, and insertion operations have logarithmic complexity. Maps are usually implemented as red-black trees.std::multisetis an associative container that contains a sorted set of objects of type Key. Unlike set, multiple keys with equivalent values are allowed. Sorting is done using the key comparison function Compare. Search, insertion, and removal operations have logarithmic complexity.std::multimapis an associative container that contains a sorted list of key-value pairs, while permitting multiple entries with the same key. Sorting is done according to the comparison functionCompare, applied to the keys. Search, insertion, and removal operations have logarithmic complexity.
Unordered Container
无序容器的基本原理:
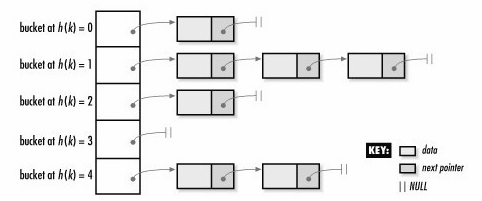
无序容器在存储上组织为一组桶 (bucket),每个桶保存零个或者多个元素;无序容器需要使用一个 hash 函数将关键字映射到桶,如果容器允许重复关键字,相同的关键字都在一个桶里面;为了访问一个元素,容器首先会计算关键字的 hash 值,找到应该搜索的桶,然后在对应的桶中搜索;所以无序容器的性能依赖于 hash 函数的质量和桶的数量和大小;
Internally, the elements are not sorted in any particular order, but organized into buckets. Which bucket an element is placed into depends entirely on the hash of its key. Keys with the same hash code appear in the same bucket. This allows fast access to individual elements, since once the hash is computed, it refers to the exact bucket the element is placed into.
![ch11-unordered_map-data-structure]()
无序容器的算法复杂度
Unordered map is an associative container that contains key-value pairs with unique keys. Search, insertion, and removal of elements have average constant-time complexity.
Unordered set is an associative container that contains a set of unique objects of type Key. Search, insertion, and removal have average constant-time complexity.
无序容器的迭代器失效问题
std::unordered_mapandstd::unordered_set一样Operations Invalidated All-read-only operations Never swap, std::swap Never, swap functions do not invalidate any of the iterators inside the container, but they do invalidate the iterator marking the end of the swap region. clear, rehash, reserve, operator= Always invalidate iterator, References and pointers to data stored in the container are only invalidated by erasing that element, even when the corresponding iterator is invalidated. insert, emplace, emplace_hint, operator[] Only invalidate iterator if causes rehash; References and pointers to data stored in the container are only invalidated by erasing that element, even when the corresponding iterator is invalidated. erase Only to the element erased. References and pointers to data stored in the container are only invalidated by erasing that element, even when the corresponding iterator is invalidated. std::move After container move assignment, unless elementwise move assignment is forced by incompatible allocators, references, pointers, and iterators (other than the end iterator) to moved-from container remain valid, but refer to elements that are now in *this.自定义 hash 函数
默认情况下,无序容器使用
==运算符来比较元素,他们还使用一个hash<key_type>类型的对象来生成每个元素的哈希值标准库为内置类型和一些标准库的模版 (比如 string) 都已经生成了 hash 模版,所以可以直接定义
Key为内置类型的无序容器不能直接定义自定义类型作为无序容器 Key 的类型,因为这些类型不能直接使用
hash模版,而需要提供自定义类型的 hash 模版;当然,我们也可以不使用默认的 hash,而是提供函数来代替==运算符和哈希值计算函数;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// hash: std::hash<key>
size_t hasher(const Sales_data& sd){
return std::hash<std::string>()(sd.isbn());
}
bool equal_op(const Sales_data &lhs, const Sales_data &rhs){
return lhs.isbn() == rhs.isbn();
}
using SD_multiset = unordered_multiset<Sales_data, delctype(hasher)*, decltype(equal_op)*>;
SD_multiset book_store(42, hansher, equal_op);
// equivalent
std::unordered_multiset<Sales_data, delctype(hasher)*, decltype(equal_op)*> bookstore(42, hasher, equal_op);
无序容器的桶 (bucket) 的管理
1
2
3
4
5
6
7
8
9
10
11c.bucket_count(); // bucket size in use
c.bucket_size(n); // item size in nth bucket
c.max_bucket_count(); // bucket capacity
c.bucket(k); // which bucket index the key k exists
c.begin(n), c.end(n); // begin and end iterator of bucket n
c.load_factor(); // average keys in bucket
c.max_load_factor(); // max load factor, if load_factor > max_load_factor, c will add bucket
c.rehash(); // rehash, make bucket_count>=n and bucket_count>size/max_load_factor
c.reserve(); // like vector::reserve, not rehash1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22std::unordered_map<string,string> mymap = {
{"house","maison"},
{"apple","pomme"},
{"tree","arbre"},
{"book","livre"},
{"door","porte"},
{"grapefruit","pamplemousse"}
};
unsigned n = mymap.bucket_count();
std::cout << "mymap has " << n << " buckets" << std::endl;
for (unsigned i=0; i<n; ++i) {
std::cout << "bucket #" << i << "'s size:"<<mymap.bucket_size(i)<<" contains: ";
for (auto it = mymap.begin(i); it!=mymap.end(i); ++it)
std::cout << "[" << it->first << ":" << it->second << "] ";
std::cout << std::endl;
}
std::cout <<"key:'apple' is in bucket #" << mymap.bucket("apple") <<std::endl;
std::cout <<"key:'computer' is in bucket #" << mymap.bucket("computer") <<std::endl;
// reference: https://blog.csdn.net/hk2291976/article/details/510370951
2
3
4
5
6
7
8
9
10ymap has 7 buckets.
bucket #0's size:2 contains: [book:livre] [house:maison]
bucket #1's size:0 contains:
bucket #2's size:0 contains:
bucket #3's size:2 contains: [grapefruit:pamplemousse] [tree:arbre]
bucket #4's size:0 contains:
bucket #5's size:1 contains: [apple:pomme]
bucket #6's size:1 contains: [door:porte]
key:'apple' is in bucket #5
key:'computer' is in bucket #6